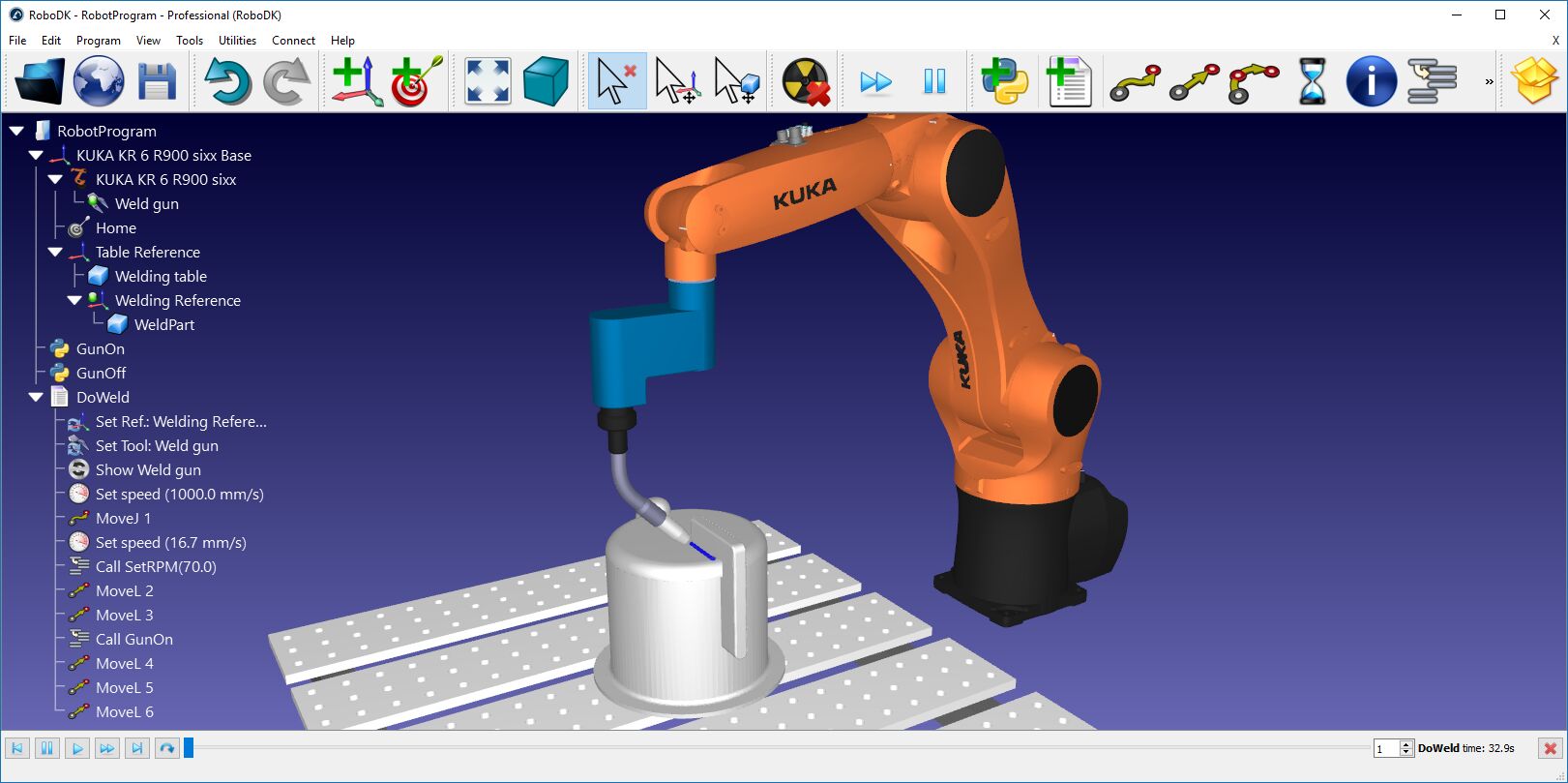
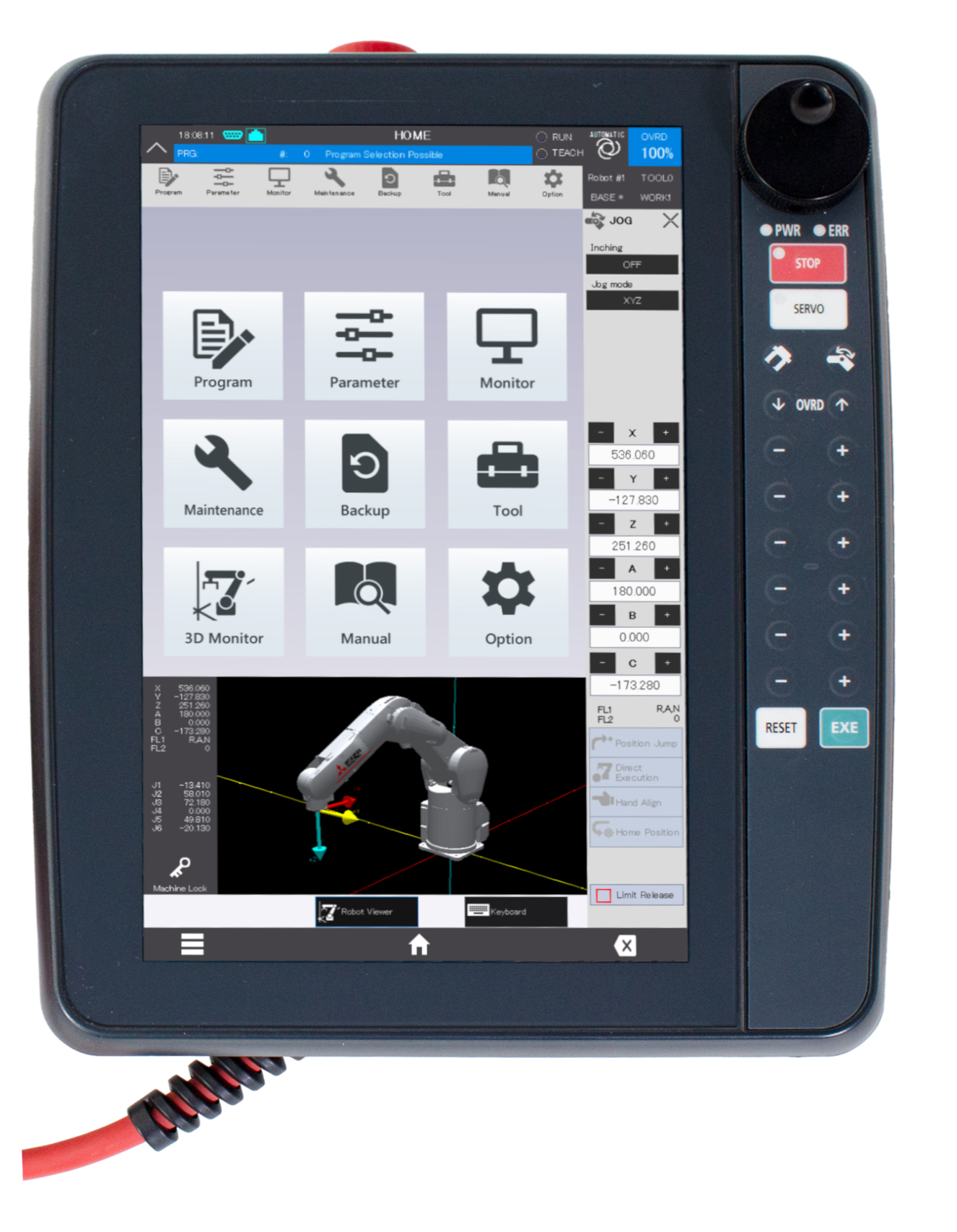
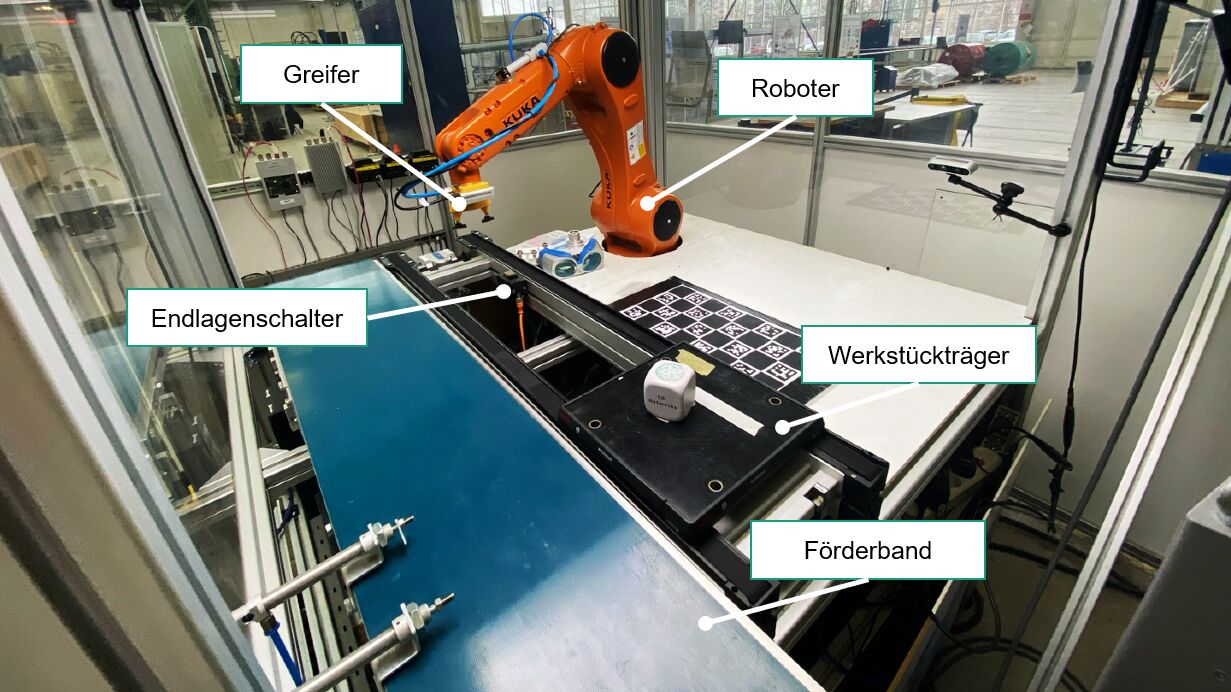
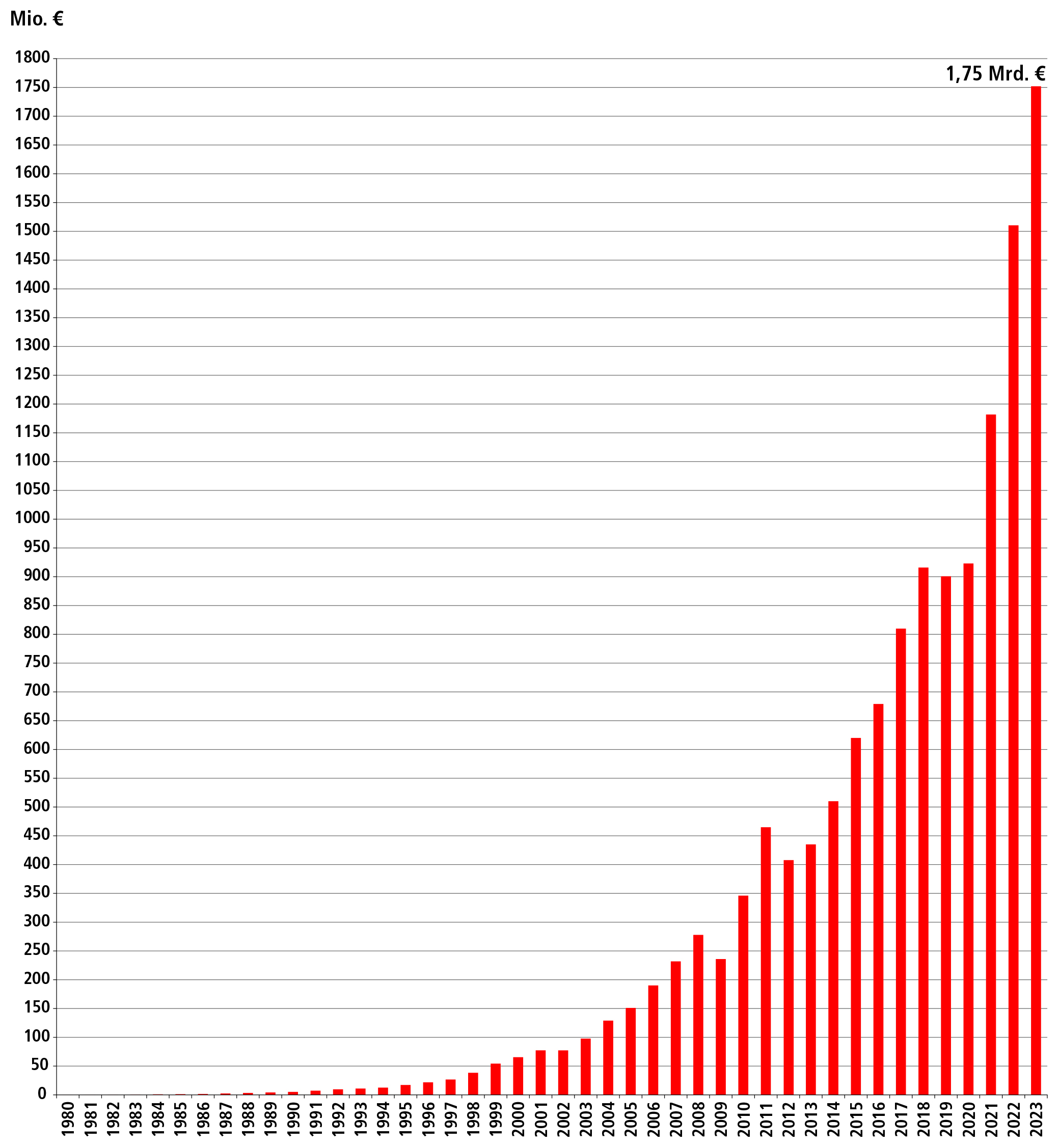
Mit Hilfe von Reinforcement-Learning-Algorithmen können Roboter auch anspruchsvolle Bewegungen in einer unbekannten Umgebung und bei unbekannten Robotermodellen erlernen – doch wie kann man sicherstellen, dass sie Sicherheitsbeschränkungen respektieren, ohne dass sich ihre Performance verschlechtert?
Bild: Amr-Alanwar, TUM Campus Heilbronn GmbH
Bild: Amr-Alanwar, TUM Campus Heilbronn GmbH
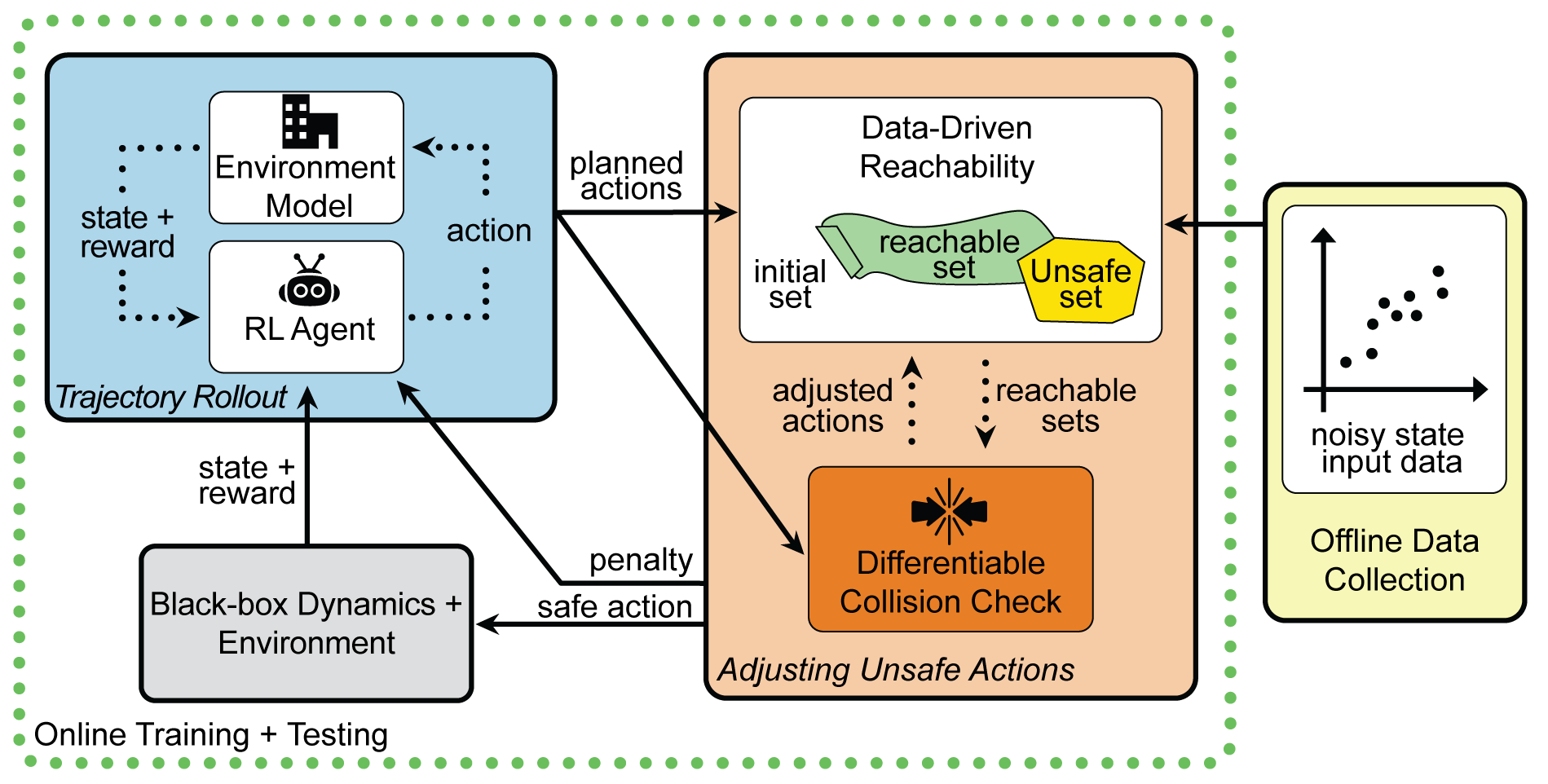
Kollisionsfrei unterwegs
mehr lesen